


Over the next three posts, I’ll be showing you how ebooks are coded and formatted.
You’ve heard me call an ebook a website in a box. This time we’re going to talk about what’s inside the box.
First things first: let me share an ebook with you. It’s the ePub file for a short story of mine called White Robes. (Clicking on this link will download the file to your device.)
You’re welcome to read it, obviously, but for the purposes of this post (and the next two), we’re going to be opening up the box and dissecting the ebook.
This is the actual production file that I’ve uploaded to Amazon, by the way — it includes all of the coding and formatting that I typically include in creating an ebook. It will be the model that I’ll be using over the next few posts in discussing an ebook’s innards.
Opening the Box
What we’re going to look this time is the structure of the ebook — the collection of files that an ePub-ready ereader like Apple’s iBooks or Barnes & Noble’s Nook or Readium or Calibre or any of thousands of other apps can open. [1]
So now we have our website in a box. Let’s open the box and see what we’ve got! [2]
There are just three steps:
Step 1: Duplicate your file
Now, I’m going to assume that you’re using a Windows or Mac computer. [3]
We’re duplicating the file so that the original doesn’t get destroyed. Just a good habit to stay in, right?
In Windows, select the file in Windows Explorer by dragging over it or left-clicking on it once. From the Organize menu at the top of the window, select Copy. (You can do the same thing by right-clicking on the file and selecting Copy.)
In Mac OS X, select the file in the Finder by dragging over it or clicking on it once. Now hit command-D or go to the File menu and select Duplicate. (You can also control-click/right-click on the file and select Duplicate.)
You should now have a duplicate copy of the file:
Step 2: Convert to ZIP format
This is actually a much simpler process than you might think: an ePub file is just a carefully constructed ZIP archive with a different extension (the last three or four letters at the end of the file name).
If you don’t see the . epub extension at the end of your new file, click on/drag over the file to select it.
In Windows, go to the Organize menu and select Folder and Search Options. De-select the Hide known file extensions option. Click OK.
In Mac OS X, go to the File menu and select Get Info or hit command-I. If not already open, click on the triangle next to the Name and Extension heading to reveal the Hide extension option and deselect it. Close the Info window.
Now rename the file.
In Windows, right-click the file name and select Rename (or left-click and hold down the button for one second). Double-click the epub file extension (not including the period!) and replace it with the extension zip. Hit the Enter button.
In Mac OS X, click once on the file and hit the Return button. Double-click the epub file extension (not including the period!) and replace it with the extension zip. Hit the Return button.
Voilà! You’ve turned your ePub ebook into a ZIP archive.
Step 3: UnZIP the file
Whether you’ve got a Mac or Windows computer, you can simply double-click on the file now to expand the archive, turning it into a regular folder/directory on your desktop.
What’s inside the Box?
What’s inside, you ask?
Well, the first thing you’ll see is two more directories (we’ll talk about those in a minute) and a file called mimetype.
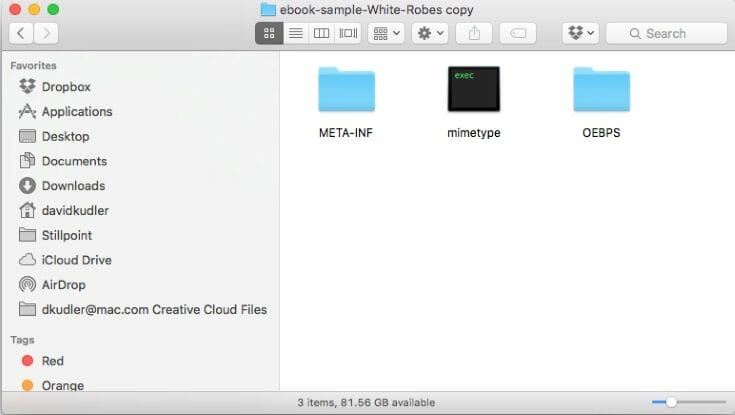
The mimetype file is a one-line piece of code that lets the ereader know what kind of file it’s reading — and that one line always reads as follows:
application/epub+zip
It’s telling the ereader that, in fact, this is an ePub file wrapped inside a ZIP archive. As if we didn’t already know that.
How about those two folders?
Well, one of them isn’t any more exciting. The META-INF folder usually contains just one file (container.xml), [4]and its sole purpose is to tell the ereader where to find the all-important OPF file. The OPF file is the traffic cop for the ebook, telling the ereader where to find everything, and what everything is. The folder where the OPF is located is called the root directory.
Sometimes the OPF is actually on the outermost level of the archive. Most often, however, you’ll find it in the OEBPS folder.
The root of the ebook: the OEBPS folder
OEBPS (Open eBook Publication Structure) is an XML-based specification for the content, structure, and presentation of electronic books. It is the blueprint on which any ePub file is built.
The OEBPS folder in any ebook will contain a number of important files, including our friend the OPS file, as well as a number of folders we’ll look at later.
Here’s the White Robes OEBPS folder:
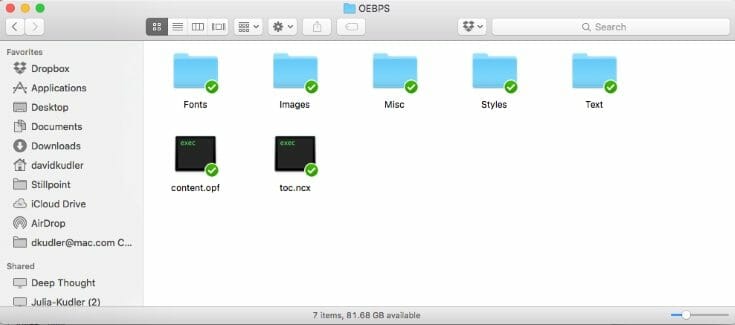
Remember: this is the root directory. Every file reference given in the ebook will be given relative to this folder.
Now the two files are of great interest:
The traffic cop: The OPF file
OPF stands for Open Packaging Format — so you’ll sometimes see the OPF referred to as the Package File. It contains all of the bibliographic and structural information about your ebook: what it is and where it is.
You can open the OPF file in any text-editing software like Notepad or TextEdit (or TextWrangler or BBEdit or whatever.) [6]
Like all of the files in an ebook, [7] the OPF file is an XML file. That means that it’s a very carefully constructed set of data, set off in series of tags, each of which has an opening and closing version, that are (almost always) used in pairs around the data, like this:
The version of the tag that starts with a forward slash (</tag>)is called the close tag.
The two important things to remember with XML tags:
1. You can nest them (place one inside another like Russian dolls.
2. You always have to close the most recently opened tag first.
Here’s how that works:
<outer tag><inner tag>[DATA]</inner tag></outer tag>
Did you see what I did there? The
Because of the way XML works, every thing that applies to the <outer tag> applies to <inner tag> unless the inner tag states otherwise. That’s called cascading, and will become more important when we talk about the HTML code that makes up most of an ebook’s content. [8]
Warning: Feel free to poke around in the OPF file for White Robes. However, unless you are really confident in what you’re doing, I highly recommend not messing around with the OPF file in an ebook you’re preparing for publication. The file is created and updated automatically by the conversion/editing software that you’re using — making changes by hand without knowing what you’re doing can break your ebook. [9]
The OPF file is made of a header that identifies the kind of file that it is (the XML and package tags in lines 1–2), and then as many as four sections:
- The metadata section, which tells the ereader information about your book.
- The manifest section, which tells the ereader where to find everything. (listing every file contained in the ebook and its address)
- The spine section, which tells the ereader in what order it should display files. (optional)
- The guide section, which tells the ereader where to find “special” files like the cover. (optional)
Here’s the OPF file for White Robes[10]
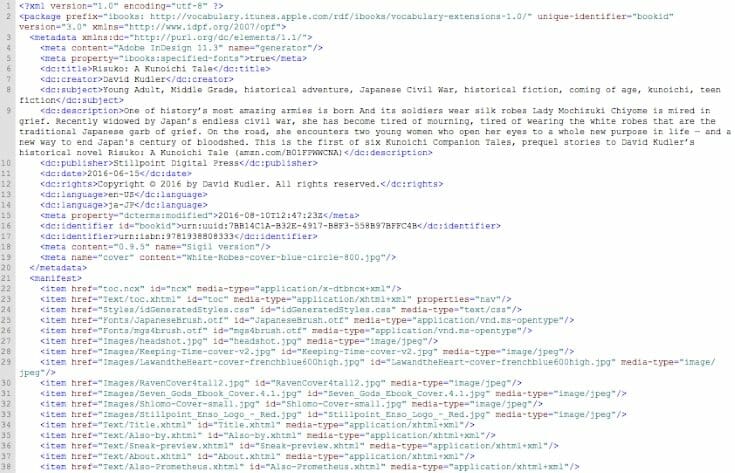
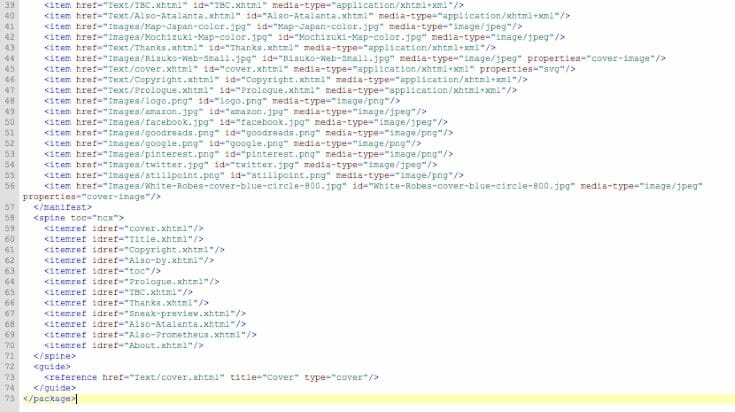
Boy, that’s a lot of stuff going on for one short story!
One interesting bit: in line 2 (along with a lot of other very important but opaque stuff) you can see the attribute version=”3.0″. This tells us that this is an ePub3 file. If the version number had been 2.0… well, you can probably guess: it would be an ePub2 file.
There are a number of other major differences between the two types of ePub file, but that’s the flag that tells an ereader to treat this file as one kind of ePub or the other.
Many of the lines begin with an open tag and end with a close tag. A number don’t. They fall into two categories:
- Some contain all of the data within the tag — for example, all of the item tags (lines 22–56). In that case, rather than have two separate tags with nothing between them (i.e., <item href=[…]></item>) XML convention allows you to close the tag by putting a slash at the end of the open tag: <item href=[…]/>
- When a tag has one or more tags nested within it. For example, look at the guide tag, on line 72. There’s a reference tag on line 73 before the guide close tag on line 74.
Each type of tag, from the various dc: (Dublin Core) metadata tags to the itemref tags, has an extremely specific syntax, and learning that is more than I could teach (or you would want to learn) here. However, you can find out more (much more) at the International Digital Publishing Forum page on OPF files. (The IDPF is the trade group responsible for the ePub format.)
One other thing that you might notice here: the addresses. Everything after an href or src attribute is a reference to a file within the ebook’s file structure. It’s exactly like one of the URLs we’re used to typing into the address bar at the top of our browser window to go to a particular web page. The only difference is that where a URL (uniform resource locator) has to give an address on the open internet, and must contain the protocol for the browser to use when it gets there (i.e., https:// , ftp:// , or mailto: ), these addresses are always relative to the current document — they’re what are called URIs — uniform resource identifiers. They don’t include the protocol — and they have to be somewhere in the current file structure of the ebook (or web page). So for instance, on line 27, there’s a reference to where to find my headshot. The URI reads Images/headshot.jpg. That tells the ereader to look inside the Images folder for the file called headshot.jpg. [11]
Note that capitalization and spelling must be precisely correct. Headshot.jpg is not the same as headshot.jpg.
The roadmap: The NCX file
The other file that almost always appears in the root directory is the NCX or navigation file.
If you’ve ever read an ebook (and if you haven’t, you really should, if only so that you can understand what your readers experience!), you’ll know that there’s a pull-down table of contents — not the contents page at the front or back of the book, but a menu available wherever you are, so that you can navigate to wherever you want to go in the book. It looks something like this:
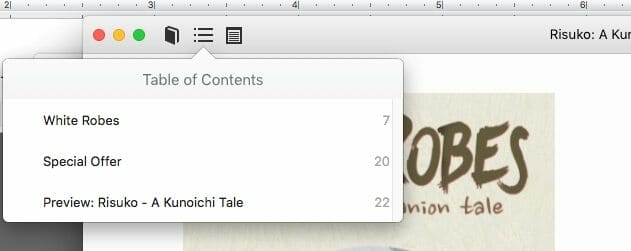
In ePub3, that menu is pulled from the table of contents page in your ebook — it’s essentially a slightly marked-up HTML page. In ePub2, you needed to create a separate file (the NCX file) to tell the ereader what to display.
Now, ePub3 is great — but not all ereaders can display it, especially the older ones. And so, for backwards compatibility (that is, so that newer software can run on older machines), it’s still a really good idea to include an ePub2-style NCX page.
Here’s what the NCX page for White Robes looks like:
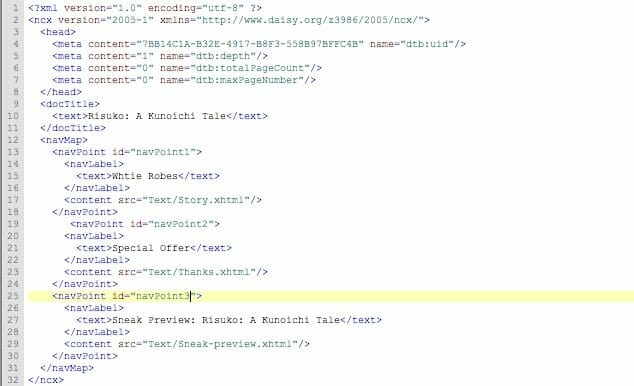
Notice that each item in the table of contents (everything inside the navMap tags) is in its own set of navPoint tags, and that the navLabel and text tags tell the ereader what to display in the menu while the content tag shows what file to send the reader to when they click on the item.
Like the OPF file, most ebook conversion and creation software will take care of this for you — but it’s good to know what’s there, in case a problem should come up.
All together now: The rest of the files
Let’s look at the OEBPS folder again:
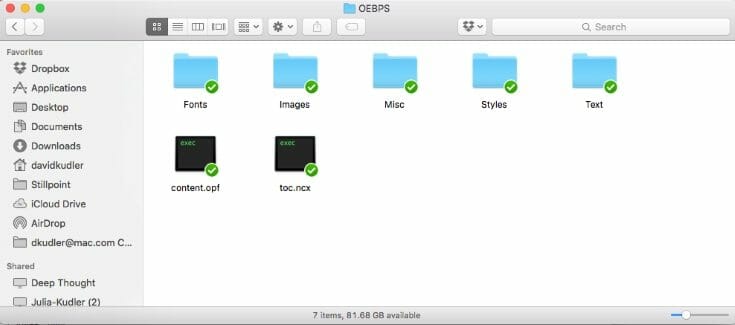
You’ll see our friends the OPF and NCX files. And then there’s all of the rest of those folders. Sigil organizes all of the files neatly so that they’re easy to find: fonts in the Fonts folder, images in the Images folder, stylesheets in the Styles folder, and so forth. (Don’t forget to capitalize correctly!)
Here are the contents of the Images folder for White Robes:
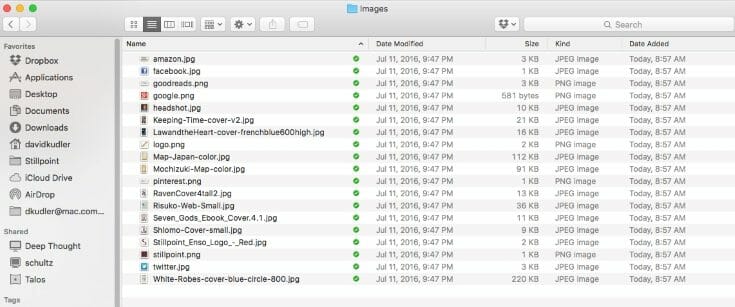
Notice that all of the image files are there — the cover, the map, and all of the little images (including covers of other books) that are scattered throughout. Notice too that I’ve optimized those images so they’re fairly small. [12]
The fonts in the Fonts folder are ones that I have the right to use in ebooks — in this case, they’ve been released into the public domain. They’re also OTF fonts (Microsoft’s OpenType font standard), which are the only ones that will work with most ereaders (and even then, not always).
There’s an XML file in the Misc folder that tells the ereader I’ve got custom fonts on board.
There’s a CSS stylesheet in the Styles folder. I’ll get to that in a couple of posts, I promise — and it will a lot more hands on than this one!
Last but not least we find the actual body of the ebook, the (X)HTML files, in the Text folder:
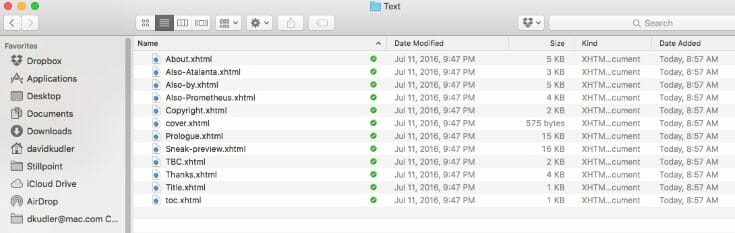
Note that they’re in alphabetical order — but that’s not how they’re displayed in the book. Remember the spine section of the OPF file? Yup. That’s what defines the order.
In any case, next month, we’re going to look at how those files are built!
Clean Up
That’s all for now. But if you want to clean up the files you’ve been poking around in, just go back until you see the folder that contained the ebook:
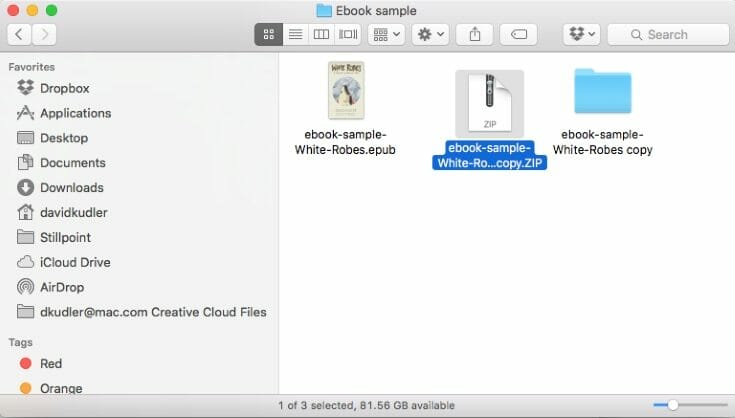
In Windows, select the folder (“ebook-sample-White-Robes-copy”), right-click on it, and then select Send to, and then Compressed (zipped) folder. Then change the extension back to .epub.
For Macs, this part is a bit more complicated; OS X adds invisible files that mess with the ePub file structure. The easiest way to re-ZIP the ebook is to use a little freeware script called Zip/Unzip. It’s not a new script (version 3 is at least five years old), but it still works wonderfully. Drag your file onto the script, and it will take care of re-compressing your folder and renaming the archive with the proper .epub extension.
[1] Not Kindle. As we’ve discussed, Amazon’s Kindles and Kindle apps use proprietary file formats. You can convert an ePub file to Kindle formats, but you can’t open up a Kindle file and poke around inside the way we’re going to be doing here, so I won’t bother including a Kindle version of the file. However, just to repeat what I’ve pointed out before, this ePub file is the best format to upload to Amazon! (Please don’t upload this one, though — it’s mine!)
[2] Okay: you don’t have to do this to create/edit ebooks. You can in fact get at the files inside of an ebook without opening it up using applications like Sigil and Calibre. You can even look at the file structure and edit individual files in those apps. We’re doing this the old-fashioned way, however. Think of this as a high-school science lab, only instead of slicing open a frog, you’re opening up an ePub file. Much less messy!
[3] Linux users are usually pretty savvy and don’t need instructions on how to manipulate files. As for iOS and Android users… Well, opening up and editing an ebook on a tablet or phone isn’t yet terribly practical. It can be done, but it isn’t fun, so I don’t recommend it.
[4] Okay: occasionally there is another file or two — often put there to let the ereader know that there are fonts or other special files on board. But that’s advanced stuff for another day.
[5] This is necessary only for ePub2 files — however, it’s good to include one in ePub3 files, so that older ereaders can open them.
[6] But not a word-processing app like Microsoft Word! Word, etc., will turn all of the quotation marks to “curly” or “smart” quotes — which will render the files useless.
[7] Excepting media files (like images, video, and audio), scripts, fonts, or CSS files — but more on those a couple of posts from now. By the way, aside from the media files, most of the files on your computer are probably some flavor of XML (or packages of XML files).
[8] HTML is simply a form of XML that has been adapted for displaying web pages.
[9] If you’d like to know more about the workings of the OPF file, I recommend going to the IDPF.org pages for the ePub2 and ePub3 formats, or check out Liz Castro’s great nuts-and-bolts intro to ePub creation [ePub: Straight and to the Point or Jared Buse’s [ePub from the Ground Up, which is a bit more up-to-date, and touches more on ePub3.
[10] Screenshots taken in Sigil. The indentation and coloring should help you see what goes with what.
[11] You want fine distinctions? Images/headshot.jpg tells the ereader to look inside the folder Images inside the current folder. /Images/headshot.jpg (see the slash at the beginning?) tells the ereader to look for the Images folder in the root directory —which it is in this case, but might not be in other cases. The most common way to look for a file in a different folder? Use this syntax: ../Images/headshot.jpg. That tells the ereader to go up one folder, look for the Images folder, and then find the file headshot.jpg. Whew!
[12] I almost always optimize after I’ve imported the files — this is a major reason that I open up ePub files like this.
Photo: pixabay.com. Amazon links contain my affiliate code.
